Polar Sparsity: High Throughput Batched LLM Inferencing with Scalable Contextual Sparsity
Abstract
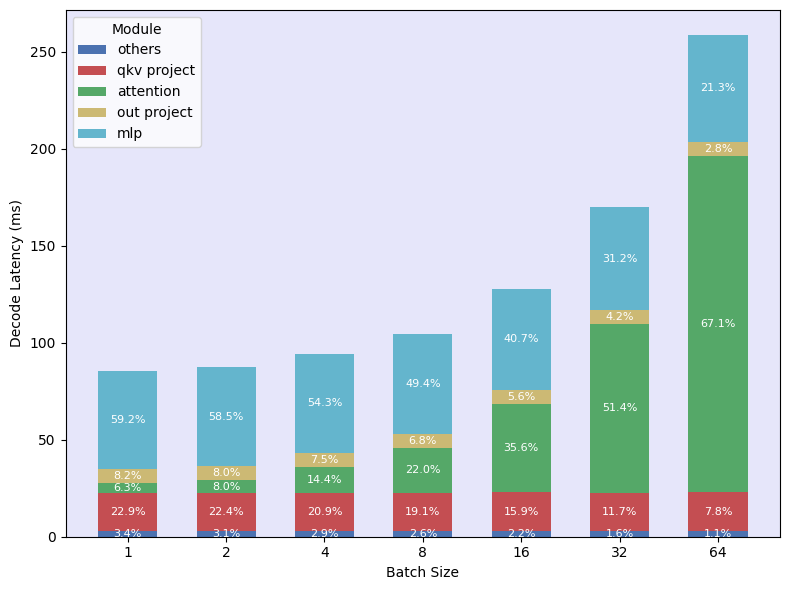
Accelerating large language model (LLM) inference is critical for real-world deployments requiring high throughput and low latency. Contextual sparsity, where each token dynamically activates only a small subset of the model parameters, shows promise but does not scale to large batch sizes due to union of active neurons quickly approaching dense computation. We introduce Polar Sparsity, highlighting a key shift in sparsity importance from MLP to Attention layers as we scale batch size and sequence length. While MLP layers become more compute-efficient under batching, their sparsity vanishes. In contrast, attention becomes increasingly more expensive at scale, while their head sparsity remains stable and batch-invariant.
We develop Selective Head Attention with hardware-efficient, sparsity-aware GPU kernels, delivering up to 2.2x end-to-end speedups for models like OPT, LLaMA-2 & 3, Qwen, Mistral across various batch sizes and sequence lengths without compromising accuracy. To our knowledge, this is the first work to demonstrate that contextual sparsity can scale effectively to large batch sizes, delivering substantial inference acceleration with minimal changes, making Polar Sparsity practical for large-scale, high-throughput LLM deployment systems.
Polar Sparsity
Polar Sparsity refers to the shift in sparsity importance from MLP layers to Attention layers as batch size and sequence length increase. Current state-of-the-art sparsity methods primarily focus on model parameter sparsity, where only a subset of model parameters is activated to reduce computation and memory IO. We define head sparsity as the phenomenon where, for a given token, only a subset of attention heads contribute significantly to the output while the remaining heads have negligible effect.
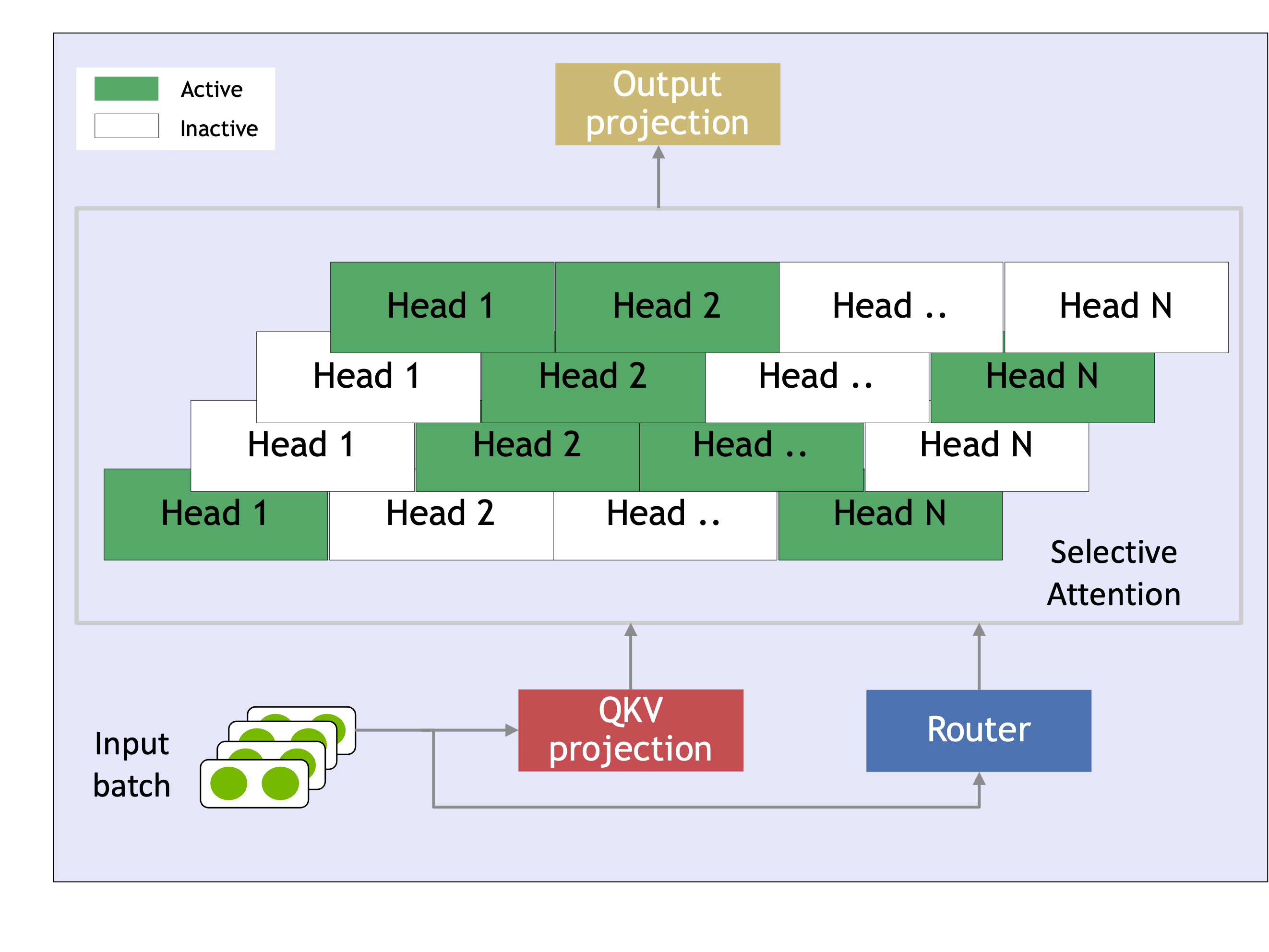
In large-batch inference, the cost of accessing model parameters is largely amortized, since the entire batch utilizes the same model weights. In contrast, each batch has a unique key-value (KV) cache, making attention layers memory I/O expensive. While contextual sparsity in model parameters diminishes as batch sizes increase, attention head sparsity remains stable and batch invariant. We introduce Selective Head Attention, which activates only the most critical heads for each request, preserving overall sparsity and improving compute and memory efficiency.
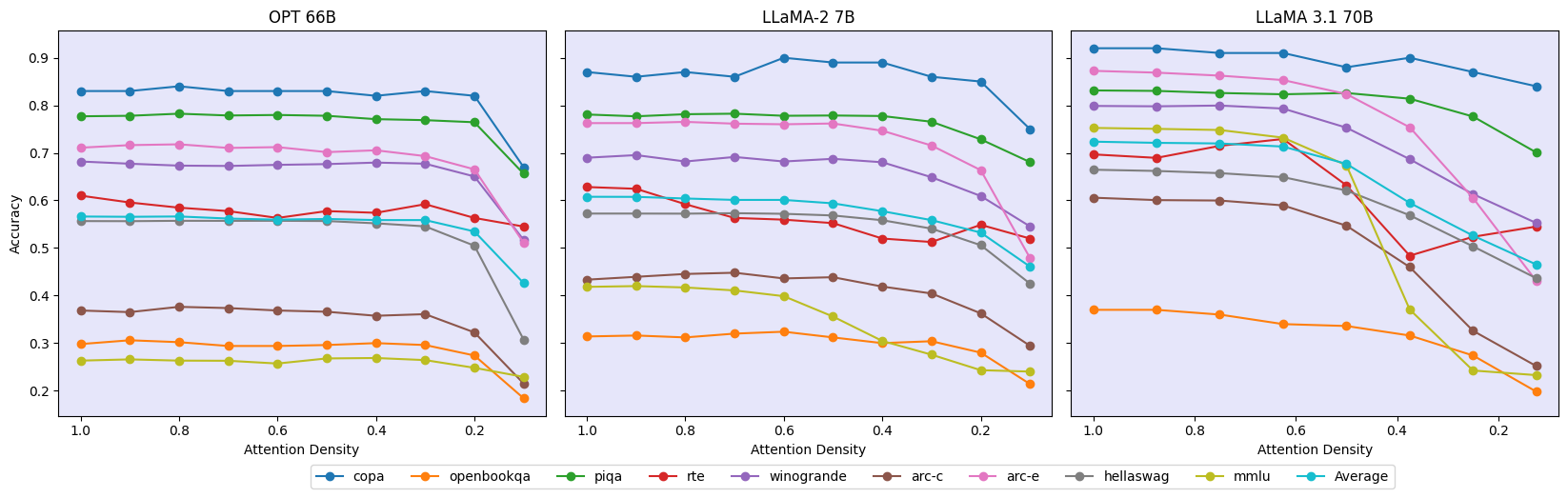
Accuracy vs. Attention Density
Figure 3 shows the zero-shot accuracy on downstream tasks as we vary the attention density. At each data point, we activate the attention heads/groups with the highest output logits as predicted by the routers. Across all models, we observe that most tasks can be solved accurately even under high attention head sparsity with minimal degradation up to a critical threshold. The evaluation results show that this critical point varies with the architecture and size of the model.
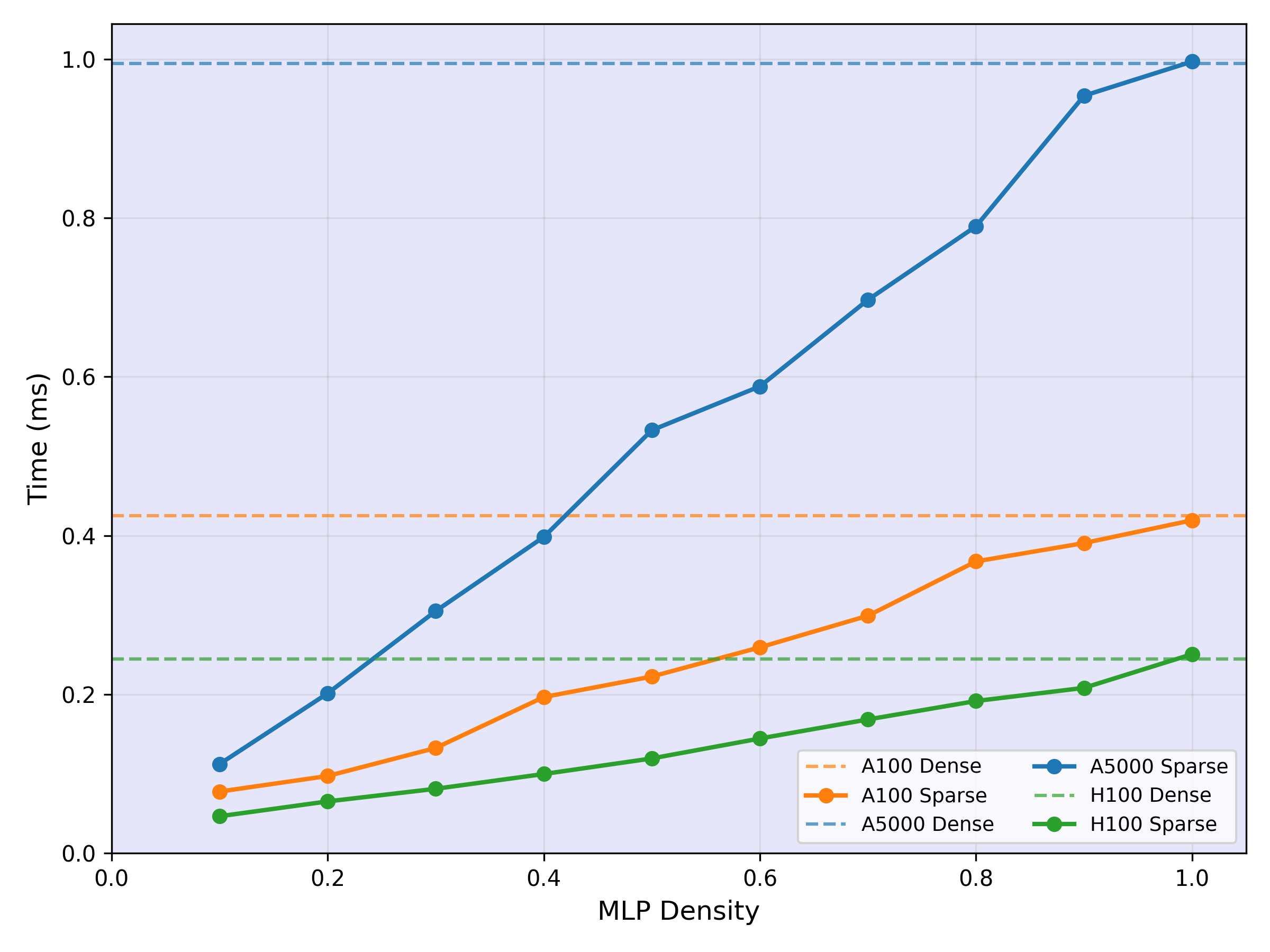
Results and Throughput
We evaluate Polar Sparsity across multiple model sizes and benchmarks, demonstrating consistent speedups with minimal accuracy loss. We build contextual sparsity-aware custom Selective GEMM and Selective FlashAttention kernels that reduce memory I/O and compute, enabling scalable and high-throughput inference.
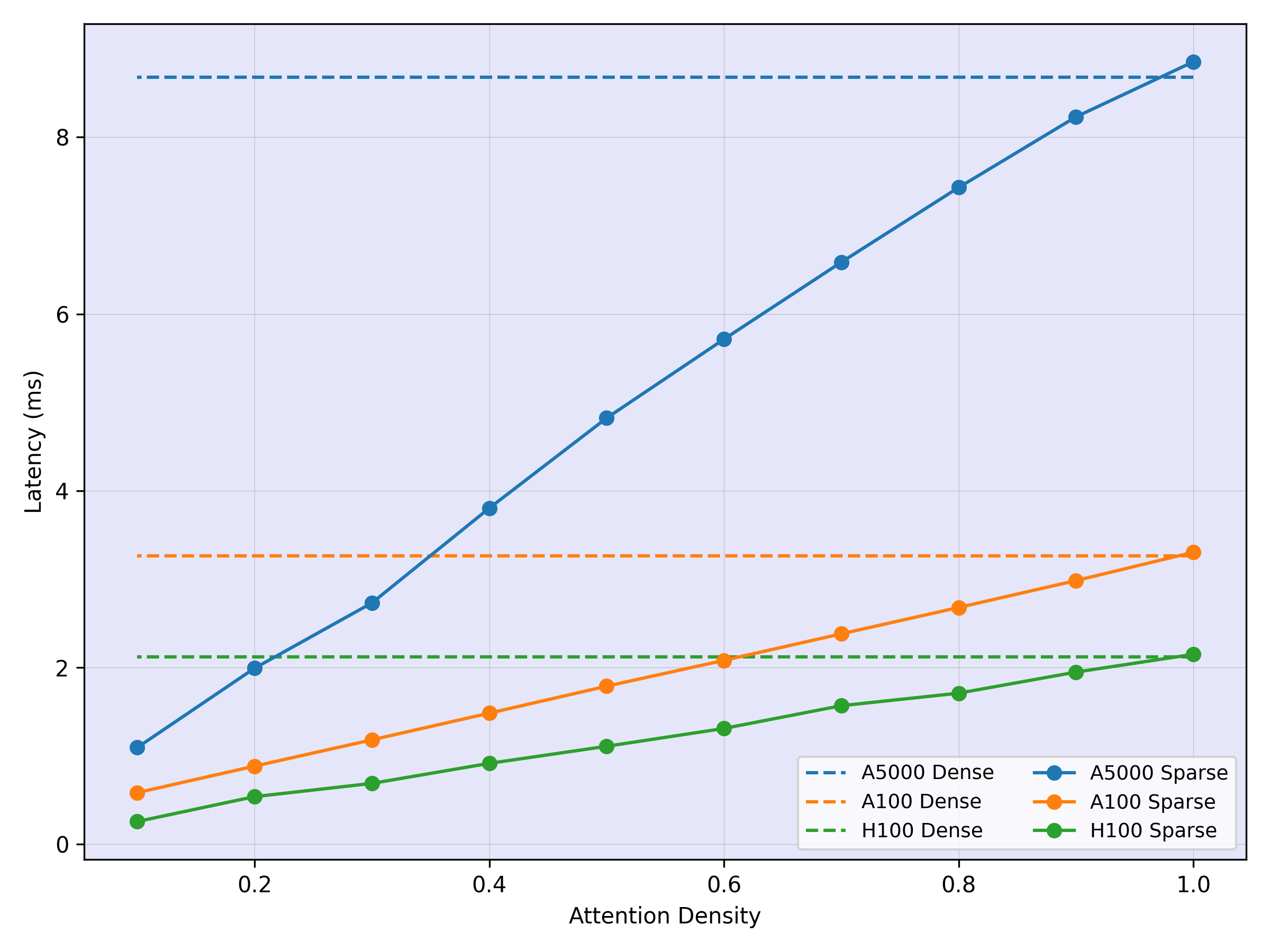
Kernel Speedup
Zero-Shot Benchmark Results
| Model | COPA | OBQA | PIQA | RTE | WG | HS | MMLU | ARC-E | ARC-C | Average |
|---|---|---|---|---|---|---|---|---|---|---|
| OPT 66B | 0.85 | 0.304 | 0.787 | 0.603 | 0.690 | 0.557 | 0.263 | 0.711 | 0.369 | 0.570 |
| OPT 66B + PS-0.3 | 0.83 | 0.296 | 0.769 | 0.592 | 0.677 | 0.546 | 0.264 | 0.693 | 0.361 | 0.560 |
| LLaMA 2 7B | 0.87 | 0.314 | 0.781 | 0.628 | 0.690 | 0.572 | 0.418 | 0.763 | 0.433 | 0.608 |
| LLaMA 2 7B + PS-0.5 | 0.89 | 0.312 | 0.779 | 0.552 | 0.687 | 0.568 | 0.356 | 0.762 | 0.439 | 0.594 |
| LLaMA 3.1 70B | 0.92 | 0.370 | 0.831 | 0.697 | 0.799 | 0.665 | 0.753 | 0.872 | 0.606 | 0.724 |
| LLaMA 3.1 70B + PS-0.625 | 0.91 | 0.340 | 0.823 | 0.729 | 0.793 | 0.650 | 0.732 | 0.853 | 0.590 | 0.712 |
| Mistral 7B | 0.92 | 0.332 | 0.803 | 0.686 | 0.738 | 0.609 | 0.591 | 0.796 | 0.489 | 0.663 |
| Mistral 7B + PS-0.5 | 0.92 | 0.340 | 0.801 | 0.671 | 0.736 | 0.608 | 0.562 | 0.793 | 0.483 | 0.657 |
Table 1: LLM zero-shot evaluation at critical thresholds. Polar Sparsity (PS) is competitive with the dense baseline with average accuracy within 1%.
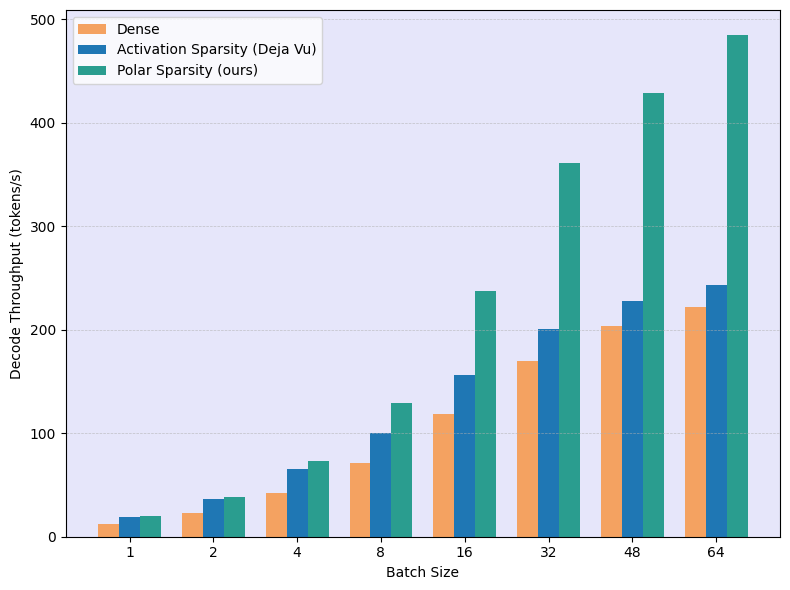
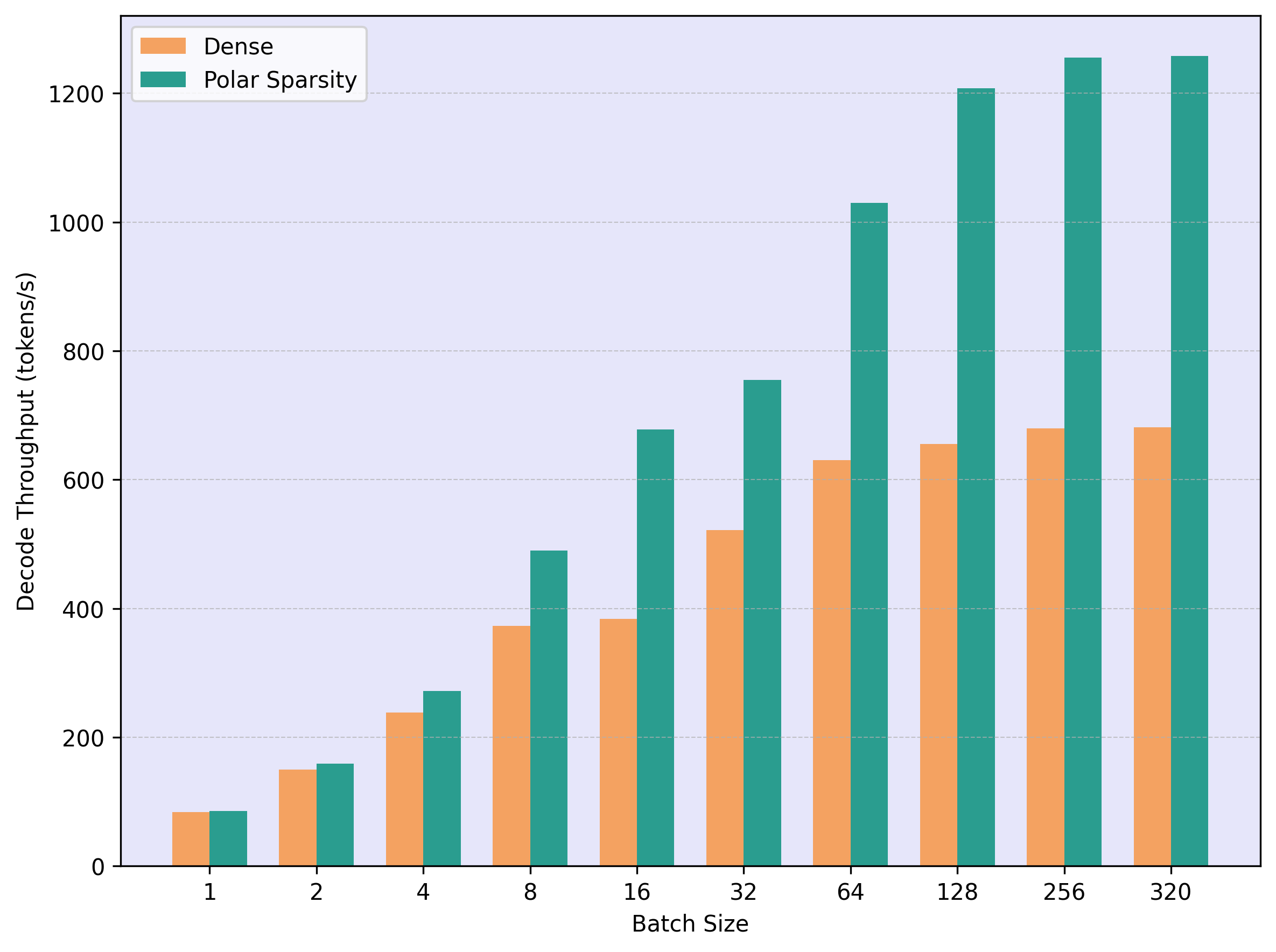
End-to-End Throughput
We measure decode throughput (tokens/second) across different batch sizes, comparing Polar Sparsity against dense baselines and state-of-the-art activation sparsity methods.
Conclusion
Our work highlights the scalability and effectiveness of contextual sparsity for accelerating batched LLM inference. We introduce Polar Sparsity, a key insight showing that as batch size and sequence length grow, the importance of sparsity transitions from MLP layers, where union activation increases, to Attention layers, where head-level sparsity remains stable and batch-invariant. To exploit this property, we develop Selective Head Attention with sparsity-aware GPU kernels that execute computations only for activated heads and neurons. Together, these optimizations deliver consistent speedups across a wide range of models, batch sizes, and sequence lengths with minimal impact on accuracy. Our results are competitive with state-of-the-art approaches and delivers up to 2.2x end-to-end speedups in large-scale settings, affirming the practical viability of Polar Sparsity for efficient and scalable LLM serving. This method is a step towards realizing scalable, high-performance, batched LLM inference that meets the growing demands of modern applications.
Citation
@misc{shrestha2025polarsparsityhighthroughput,
title={Polar Sparsity: High Throughput Batched LLM Inferencing with Scalable Contextual Sparsity},
author={Susav Shrestha and Brad Settlemyer and Nikoli Dryden and Narasimha Reddy},
year={2025},
eprint={2505.14884},
archivePrefix={arXiv},
primaryClass={cs.LG},
url={https://arxiv.org/abs/2505.14884},
}